PCIe Encoding Evolution: Why 20% Overhead Was Too High to Handle
PCIe’s leap to Gen 5 and Gen 6 wasn’t just about higher speeds—it required a fundamental rethink of how data is encoded.
PCIe didn’t scale to Gen 5 and Gen 6 speeds by simply increasing frequency.
A major breakthrough — often called the “Gen 3 Unlock” — came from fundamentally rethinking how data is encoded.
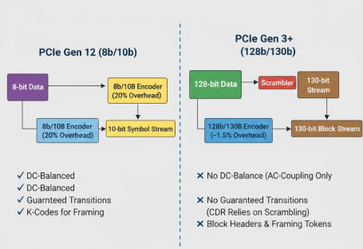
By moving from 8b/10b to 128b/130b encoding, PCIe reduced encoding overhead from 20% to ~1.5%.
This efficiency gain, however, introduced new design challenges.
🧱 The 8b/10b “Comfort Zone” (Gen 1 & Gen 2)
In early PCIe generations, 8b/10b encoding acted as a safety net by guaranteeing:
- DC Balance
- Achieved using Running Disparity to prevent voltage drift
- Transition Density
- Ensured frequent 0→1 and 1→0 transitions so the Clock Data Recovery (CDR) remained locked
- K-Codes
- Special control symbols (COM, SKP, FTS, etc.) that were easy to detect in the data stream
This simplicity made PHY design easier but came at a significant bandwidth cost.
🔧 Gen 3+ Trade-off: Efficiency vs. Complexity
With 128b/130b encoding introduced at 8.0 GT/s, many of the built-in guarantees of 8b/10b disappeared. Modern PCIe PHYs compensate through the following mechanisms:
- Scrambling Takes Center Stage
- A robust LFSR (Linear Feedback Shift Register) randomizes data
- Prevents long runs of zeros or ones
- Maintains sufficient transition density for CDR operation
- Sync Headers Replace K-Codes
- A 2-bit Sync Header identifies block type:
10b→ Data01b→ Ordered Sets- This is the only unscrambled portion of the stream
- Managing DC Wander
- Loss of inherent DC balance is handled via tighter AC-coupling capacitor specifications
- Typical values moved toward the 176–265 nF range
📦 The Two-Level Framing Model in Modern PCIe
PCIe Gen 3/4/5 uses a two-layer framing architecture:
1️⃣ Block Level
- Fixed 130-bit blocks
- Sync Header tells the receiver exactly what type of block it is processing
2️⃣ Stream Level
- Uses Framing Tokens instead of single K-characters:
- STP – Start of TLP
- SDP – Start of DLLP
- END – End of packet
- Defined using specific bit patterns within the stream
💡 Key Takeaway
128b/130b encoding is a classic engineering trade-off:
- ❌ Simpler hardware logic was sacrificed
- ✅ Massive bandwidth efficiency was gained
Without this transition, scaling to:
- 32 GT/s (PCIe Gen 5)
- 64 GT/s (PCIe Gen 6)
would have been physically impossible due to power consumption and signal-integrity limits.
Designers:
Do you miss the simplicity of 8b/10b K-codes, or has block-based encoding made your life easier in the long run?
By Krishnan B
Technology Specialist
Embedded
No comments yet. Login to start a new discussion Start a new discussion